Does RLVR Really Improve Reasoning Beyond the Base Model?
An exploration of why RL with verifiable rewards improves sampling efficiency but may not expand a model’s reasoning capabilities.
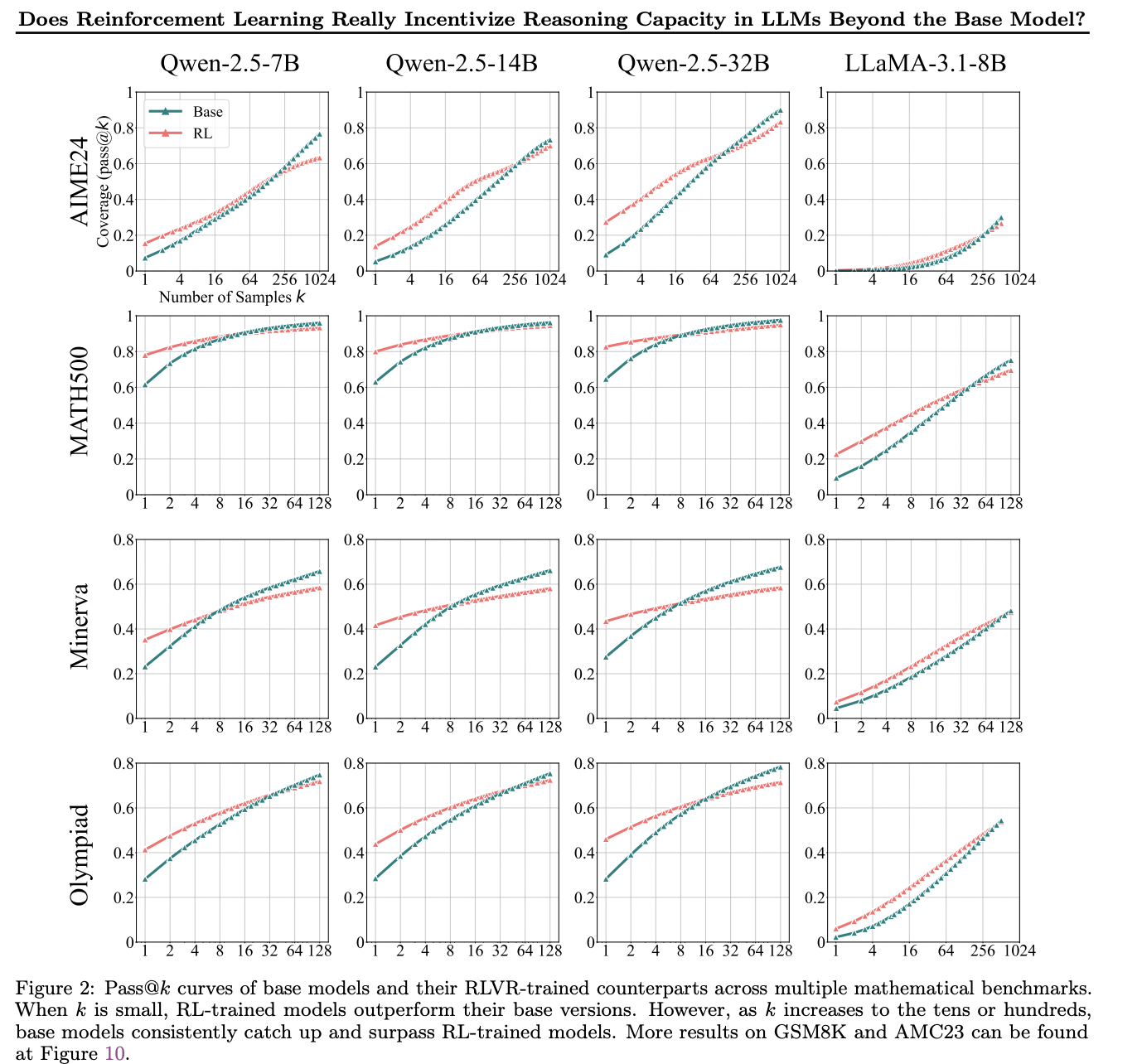
Based on my experiments, RLVR algorithms (Reinforcement Learning with Verifiable Rewards) do not appear to introduce fundamentally new reasoning capabilities beyond those of the base model.
While working with GRPO, I observed a consistent pattern. After training the base model with GRPO:
- Pass@2 improves
- Pass@100 does not
Pass@K = the proportion of tasks in the evaluation set for which at least one correct solution appears among the top-K sampled generations.
This pattern is important.
An improvement in Pass@2 without a corresponding gain in Pass@100 suggests that RLVR is not expanding the model’s solution space or introducing new reasoning paths. Instead, it is reshaping probability mass toward correct reasoning trajectories that the base model could already generate — but sampled inconsistently.
This behavior is expected given how most RLVR algorithms work:
- Sample multiple candidate solutions
- Score them (often with a verifier or sparse reward)
- Update the model to change the probability of trajectories according to their rewards
Crucially:
- If no correct solution appears among the sampled candidates, the model receives little to no learning signal.
- If a correct solution does appear, we update the model to increase the probability of the token trajectory that led to that solution.
In this regime, RLVR cannot invent new correct reasoning trajectories — it can only amplify existing ones that the base model could already generate.
Practical Takeaway
RLVR algorithms act as a probability sharpener, not a capability creator.
Before investing in RLVR for reasoning models:
- Compare Pass@2 vs Pass@20 (or another modest K)
- Small gap → RLVR likely won’t help; improve the base model
- Large gap → RLVR can be effective by sharpening sampling toward correct paths
Strong reasoning still comes primarily from strong pretraining (the base model).
I later found a paper with more extensive experiments reporting the same effect:
https://arxiv.org/pdf/2504.13837